Análisis del estado y evolución de los embalses de agua nacionales



Fecha del documento: 21-07-2022

1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información en forma de conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre los embalses nacionales. A partir de estos datos realizaremos el análisis de su estado y de su evolución temporal en los últimos años.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio para la Transición Ecológica y el Reto Demográfico, que dentro del boletín hidrológico recoge series temporales de datos sobre él volumen de agua embalsada de los últimos años para todos los embalses nacionales con una capacidad superior a 5hm3. Datos históricos del volumen de agua embalsada disponibles en:
También se ha seleccionado un conjunto de datos geoespaciales. Durante su búsqueda, se han encontrado dos posibles archivos con datos de entrada, el que contiene las áreas geográficas correspondientes a los embalses de España y el que contiene las presas que incluye su geoposicionamiento como un punto geográfico. Aunque evidentemente no son lo mismo, embalses y presas guardan relación y para simplificar este ejercicio práctico optamos por utilizar el archivo que contiene la relación de presas de España. Inventario de presas disponible en: https://www.mapama.gob.es/ide/metadatos/index.html?srv=metadata.show&uuid=4f218701-1004-4b15-93b1-298551ae9446 , concretamente:
Este conjunto de datos contiene geolocalizadas (Latitud, Longitud) las presas de toda España con independencia de su titularidad. Se entiende por presa, aquellas estructuras artificiales que, limitando en todo o en parte el contorno de un recinto enclavado en el terreno, esté destinada al almacenamiento de agua dentro del mismo.
Para generar los puntos geográficos de interés se realiza un procesamiento mediante la herramienta QGIS, cuyos pasos son los siguientes: descargar el archivo ZIP, cargarlo en QGIS y guardarlo como CSV incluyendo la geometría de cada elemento como dos campos que especifican su posición como un punto geográfico (Latitud y Longitud).
También se he realizado un filtrado para quedarnos con los datos correspondientes a las presas de los embalses que tengan una capacidad mayor a 5hm3
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación Python desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google Data Studio.
Google Data Studio es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Enriquecimiento de los datos
Con la finalidad de aportar mayor información relacionada a cada una de las presas en el dataset con datos geoespaciales, se realiza un proceso de enriquecimiento de datos explicado a continuación.
Para ello vamos a utilizar una herramienta útil para este tipo de tarea, OpenRefine. Esta herramienta de código abierto permite realizar múltiples acciones de preprocesamiento de datos, aunque en esta ocasión la usaremos para llevar a cabo un enriquecimiento de nuestros datos mediante la incorporación de contexto enlazando automáticamente información que reside en el popular repositorio de conocimiento Wikidata.
Una vez instalada la herramienta en nuestro ordenador, al ejecutarse se abrirá una aplicación web en el navegador, en caso de que eso no ocurriese, se accedería a dicha aplicación tecleando en la barra de búsqueda del navegador http://localhost:3333.
Pasos a seguir:
- Paso 1: Carga del CSV en el sistema (Figura 1).

Figura 1 - Carga de un archivo CSV en OpenRefine
- Paso 2: Creación del proyecto a partir del CSV cargado (Figura 2). OpenRefine se gestiona mediante proyectos (cada CSV subido será un proyecto), que se guardan en el ordenador dónde se esté ejecutando OpenRefine para un posible uso posterior. En este paso debemos dar un nombre al proyecto y algunos otros datos, como el separador de columnas, aunque lo más habitual es que estos últimos ajustes se rellenen automáticamente.

Figura 2 - Creación de un proyecto en OpenRefine
- Paso 3: Enlazado (o reconciliación, usando la nomenclatura de OpenRefine) con fuentes externas. OpenRefine nos permite enlazar recursos que tengamos en nuestro CSV con fuentes externas como Wikidata. Para ello se deben realizar las siguientes acciones (pasos 3.1 a 3.3):
- Paso 3.1: Identificación de las columnas a enlazar. Habitualmente este paso suele estar basado en la experiencia del analista y su conocimiento de los datos que se representan en Wikidata. Como consejo, habitualmente se podrán reconciliar o enlazar aquellas columnas que contengan información de carácter más global o general como nombres de países, calles, distritos, etc., y no se podrán enlazar aquellas columnas como coordenadas geográficas, valores numéricos o taxonomías cerradas (tipos de calles, por ejemplo). En este ejemplo, hemos encontrado la columna NOMBRE que contiene el nombre de cada embalse que puede servir como identificador único de cada ítem y puede ser un buen candidato para enlazar.
- Paso 3.2: Comienzo de la reconciliación. Comenzamos la reconciliación como se indica en la figura 3 y seleccionamos la única fuente que estará disponible: Wikidata(en). Después de hacer clic en Start Reconciling, automáticamente comenzará a buscar la clase del vocabulario de Wikidata que más se adecue basado en los valores de nuestra columna.

Figura 3 – Inicio del proceso de reconciliación de la columna NOMBRE en OpenRefine
- Paso 3.3: Selección de la clase de Wikidata. En este paso obtendremos los valores de la reconciliación. En este caso como valor más probable, seleccionamos el valor de la propiedad “reservoir” cuya descripción se puede ver en https://www.wikidata.org/wiki/Q131681, que corresponde a la descripción de un “lago artificial para acumular agua”. Únicamente habrá que pulsar otra vez en Start Reconciling.
OpenRefine nos ofrece la posibilidad de mejorar el proceso de reconciliación agregando algunas características que permitan orientar el enriquecimiento de la información con mayor precisión. Para ello ajustamos la propiedad P4568 cuya descripción se corresponde con el identificador de un embalse en España, en el SNCZI-Inventario de Presas y Embalses, como se observa en la figura 4.

Figura 4 - Selección de la clase de Wikidata que mejor representa los valores de la columna NOMBRE
- Paso 4: Generar una nueva columna con los valores reconciliados o enlazados. Para ello debemos pulsar en la columna NOMBRE e ir a “Edit Column → Add column based in this column”, dónde se mostrará un texto en la que tendremos que indicar el nombre de la nueva columna (en este ejemplo podría ser WIKIDATA_EMBALSE). En la caja de expresión deberemos indicar: “http://www.wikidata.org/entity/”+cell.recon.match.id y los valores aparecen como se previsualiza en la Figura 6. “http://www.wikidata.org/entity/” se trata de una cadena de texto fija para representar las entidades de Wikidata, mientras el valor reconciliado de cada uno de los valores lo obtenemos a través de la instrucción cell.recon.match.id, es decir, cell.recon.match.id(“ALMODOVAR”) = Q5369429.
Mediante la operación anterior, se generará una nueva columna con dichos valores. Con el fin de comprobar que se ha realizado correctamente, haciendo clic en una de las celdas de la nueva columna, está debería conducir a una página web de Wikidata con información del valor reconciliado.
El proceso lo repetimos para añadir otro tipo de información enriquecida como la referencia en Google u OpenStreetMap.

Figura 5 - Generación de las entidades de Wikidata gracias a la reconciliación a partir de una nueva columna
- Paso 5: Descargar el CSV enriquecido. Utilizamos la función Export → Custom tabular exporter situada en la parte superior derecha de la pantalla y seleccionamos las características como se indica en la Figura 6.

Figura 6 - Opciones de descarga del fichero CSV a través de OpenRefine
5. Preprocesamiento de datos
Durante el preprocesamiento es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creadas posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Modificación y ajuste de las variables
- Detención y tratamiento de datos ausentes (NAs)
- Generación de nuevas variables
- Creación de tabla para visualización "Evolución histórica de la reserva hídrica entre los años 2012 y 2022"
- Creación de tabla para visualización "Reserva hídrica (hm3) entre los años 2012 y 2022"
- Creación de tabla para visualización "Reserva hídrica (%) entre los años 2012 y 2022"
- Creación de tabla para visualización "Evolución mensual de la reserva hídrica (hm3) para distintas series temporales"
- Guardado de las tablas con los datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
6. Visualización de datos
Una vez hemos realizado un preprocesamiento de los datos, vamos con las visualizaciones. Para la realización de estas visualizaciones interactivas se ha usado la herramienta Google Data Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que las tablas de datos que le proporcionemos estén estructuradas adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos las siguientes:
- ¿Cuál es la localización de los embalses dentro del territorio nacional?
-
¿Qué embalses son los de mayor y menor aporte de volumen de agua embalsada (reserva hídrica en hm3) al conjunto del país?
-
¿Qué embalses poseen el mayor y menor porcentaje de llenado (reserva hídrica en %)?
-
¿Cuál es la tendencia en la evolución de la reserva hídrica en los últimos años?
¡Vamos a buscar las respuestas viendo los datos!
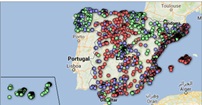
6.1. Localización geográfica y principal información de cada embalse
Esta representación visual se ha realizado teniendo en cuenta las coordenadas geográficas de los embalses y distinta información asociada a cada uno de ellos. Para ello se ha generado durante el preprocesamiento de datos la tabla “geo.csv”
Mediante un mapa de puntos geográficos se visualiza la localización de los embalses en el territorio nacional.
Una vez obtenido el mapa, pinchando en cada uno de los embalses podemos acceder a información complementaria sobre dicho embalse en la tabla inferior. También, mediante las pestañas despegables, aparece la opción de filtrar el mapa por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.2. Reserva hídrica (hm3) entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (hm3) por embalse entre los años los años 2012 (inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “volumen.csv”
Mediante un gráfico de jerarquía rectangular se visualiza de forma intuitiva la importancia de cada embalse en cuanto a volumen embalsado dentro del conjunto nacional para el periodo temporal anteriormente indicado.
Una vez obtenido el gráfico, mediante las pestañas despegables, aparece la opción de filtrar la visualización por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.3. Reserva hídrica (%) entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (%) por embalse entre los años 2012 (inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “porcentaje.csv”
Mediante un gráfico de barras se visualiza de forma intuitiva el porcentaje de llenado de cada embalse para el periodo temporal anteriormente indicado.
Una vez obtenido el gráfico, mediante las pestañas despegables, aparece la opción de filtrar la visualización por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.4. Evolución histórica de la reserva hídrica entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta los datos históricos de la reserva hídrica (hm3 y %) para todas las mediciones semanales registradas entre los años 2012(inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “lineas.csv”
Mediante gráficos de líneas y sus líneas de tendencia se visualiza la evolución temporal de la reserva hídrica (hm3 y %).
Una vez obtenido el gráfico, mediante las pestañas desplegables, podemos modificar la serie temporal, filtrar por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.5. Evolución mensual de la reserva hídrica (hm3) para distintas series temporales
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (hm3) de los distintos embalses desglosada por meses para distintas series temporales (cada uno de los años desde el 2012 hasta el 2022). Para ello se ha generado durante el preprocesamiento de datos la tabla “lineas_mensual.csv”
Mediante un gráfico de líneas se visualízala la reserva hídrica mes a mes para cada una de las series temporales.
Una vez obtenido el gráfico, mediante las pestañas desplegables, podemos filtrar por demarcación hidrográfica y por embalse. También tenemos la opción de elegir la serie o series temporales (cada uno de los años desde el 2012 hasta el 2022) que queremos visualizar mediante el icono que aparece en la parte superior derecha del gráfico.
Ver la visualización en pantalla completa
7. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implementar se puede observar lo siguiente:
-
Se observa una tendencia significativa en la disminución del volumen de agua embalsada por el conjunto de embalses nacionales entre los años 2012 y 2022.
-
El año 2017 es el que presenta valores más bajos de porcentaje de llenado total de los embalses, llegando a ser este inferior al 45% en ciertos momentos del año.
-
El año 2013 es el que presenta valores más altos de porcentaje de llenado total de los embalses, llegando a ser este superior al 80% en ciertos momentos del año.
Cabe destacar que en las visualizaciones tienes la opción de filtrar por demarcación hidrográfica y por embalse. Te animamos a lo que lo hagas para sacar conclusiones más específicas de las demarcaciones hidrográficas y embalses que estés interesado.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!