




Análisis predictivo del consumo eléctrico en la ciudad de Barcelona



Fecha del documento: 27-11-2023
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada uno de estos ejercicios prácticos, se utilizan desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El principal objetivo de este ejercicio es mostrar cómo realizar, de una forma didáctica, un análisis predictivo de series temporales partiendo de datos abiertos sobre el consumo de electricidad en la ciudad de Barcelona. Para ello realizaremos un análisis exploratorio de los datos, definiremos y validaremos el modelo predictivo, para por último generar las predicciones junto a sus gráficas y visualizaciones correspondientes.
Los análisis predictivos de series temporales son técnicas estadísticas y de aprendizaje automático que se utilizan para prever valores futuros en conjuntos de datos que se recopilan a lo largo del tiempo. Estas predicciones se basan en patrones y tendencias históricas identificadas en la serie temporal, siendo su objetivo principal anticipar cambios y eventos en función de datos pasados.
El conjunto de datos abiertos inicial consta de registros desde el año 2019 hasta el año 2022 ambos inclusive, por otra parte, las predicciones las realizaremos para el año 2023, del cual no tenemos datos reales.
Una vez realizado el análisis, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la predicción futura de consumo eléctrico?
- ¿Cómo de preciso ha sido el modelo con la predicción de datos ya conocidos?
- ¿Qué días tendrán un consumo máximo y mínimo según las predicciones futuras?
- ¿Qué meses tendrán un consumo medio máximo y mínimo según las predicciones futuras?
Estas y otras muchas preguntas pueden ser resueltas mediante las visualizaciones obtenidas en el análisis que mostrarán la información de una forma ordenada y sencilla de interpretar.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre el consumo eléctrico en la ciudad de Barcelona en los últimos años. La información que aportan es el consumo en (MWh) desglosados por día, sector económico, código postal y tramo horario.
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Barcelona en el catálogo de datos.gob.es, mediante ficheros que recogen los registros de forma anual. Cabe destacar que el publicador actualiza estos conjuntos de datos con nuevos registros con frecuencia, por lo que hemos utilizado solamente los datos proporcionados desde el 2019 hasta el 2022 ambos inclusive.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización del análisis se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de las visualizaciones interactivas se ha usado la herramienta Looker Studio.
"Looker Studio", antiguamente conocido como Google Data Studio, es una herramienta online que permite realizar visualizaciones interactivas que pueden insertarse en sitios web o exportarse como archivos.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Análisis predictivo de series temporales
El análisis predictivo de series temporales es una técnica que utiliza datos históricos para predecir valores futuros de una variable que cambia con el tiempo. Las series temporales son datos que se recopilan en intervalos regulares, como días, semanas, meses o años. No es el objetivo de este ejercicio explicar en detalle las características de las series temporales, ya que nos centramos en explicar brevemente el modelo de predicción. No obstante, si quieres saber más al respecto, puedes consultar el siguiente manual.
Este tipo de análisis se basa en el supuesto de que los valores futuros de una variable estarán correlacionados con los valores históricos. Utilizando técnicas estadísticas y de aprendizaje automático, se pueden identificar patrones en los datos históricos y utilizarlos para predecir valores futuros.
El análisis predictivo realizado en el ejercicio ha sido dividido en cinco fases; preparación de los datos, análisis exploratorio de los datos, entrenamiento del modelo, validación del modelo y predicción de valores futuros), las cuales se explicarán en los próximos apartados.
Los procesos que te describimos a continuación los encontrarás desarrollados y comentados en el siguiente Notebook ejecutable desde Google Colab junto al código fuente que está disponible en nuestra cuenta de Github.
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
4.1 Preparación de los datos
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este apartado se importan los conjuntos de datos abiertos descritos en los puntos anteriores que utilizaremos en el ejercicio, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores que puedan condicionar los pasos futuros.
4.2 Análisis exploratorio de los datos (EDA)
Este apartado podrás encontrarlo en el punto 2 del Notebook.
En este apartado realizaremos un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de origen, detectar anomalías, datos ausentes, errores u outliers que pudieran afectar a la calidad de los procesos posteriores y resultados.
A continuación, en la siguiente visualización interactiva, podrás inspeccionar la tabla de datos con los valores de consumo históricos generada en el punto anterior pudiendo filtrar por periodo temporal concreto. De esta forma podemos comprender, de una forma visual, la principal información de la serie de datos.
Una vez inspeccionada la visualización interactiva de la serie temporal, habrás observado diversos valores que potencialmente podrían ser considerados como outliers, como se muestra en la siguiente figura. También podemos calcular de forma numérica estos outliers, como se muestra en el notebook.
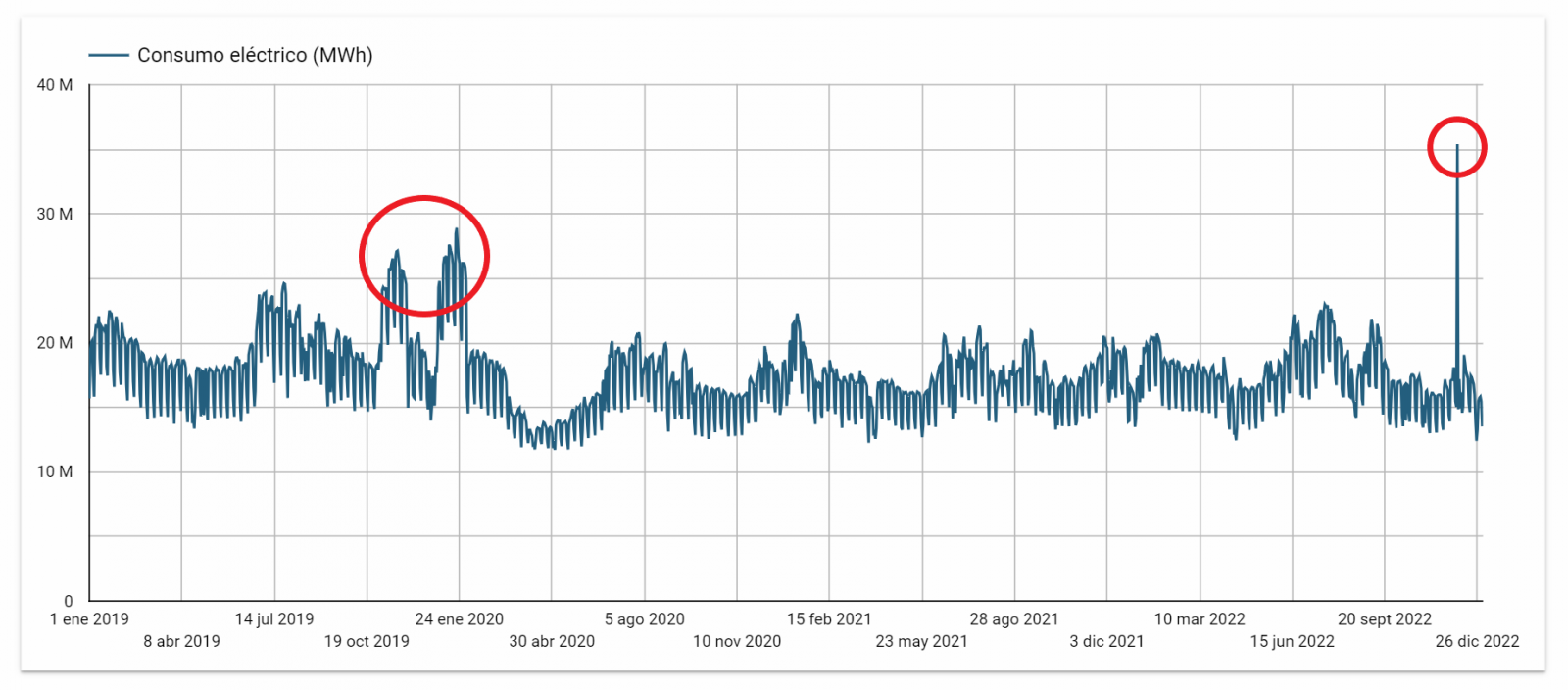
Una vez evaluados los outliers, para este ejercicio se ha decidido modificar únicamente el registrado en la fecha "2022-12-05". Para ello se sustituirá el valor por la media del registrado el día anterior y el día siguiente.
La razón de no eliminar el resto de outliers es debido a que son valores registrados en días consecutivos, por lo que se presupone que son valores correctos afectados por variables externas que se escapan del alcance del ejercicio. Una vez solucionado el problema detectado con los outliers, esta será la serie temporal de datos que utilizaremos en los siguientes apartados.

Figura 2. Serie temporal de datos históricos una vez tratados los outliers
Si quieres conocer más sobre estos procesos puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
4.3 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 3 del Notebook.
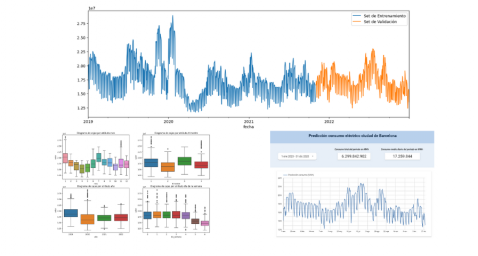
En primer lugar, creamos dentro de la tabla de datos los atributos temporales (año, mes, día de la semana y trimestre). Estos atributos son variables categóricas que ayudan a garantizar que el modelo sea capaz de capturar con precisión las características y patrones únicos de estas variables. Mediante las siguientes visualizaciones de diagramas de cajas, podemos ver su relevancia dentro de los valores de la serie temporal.

Figura 3. Diagramas de cajas de los atributos temporales generados
Podemos observar ciertos patrones en las gráficas anteriores como los siguientes:
- Los días laborales (lunes a viernes) presentan un mayor consumo que los fines de semana.
- El año que valores de consumo más bajos presenta es el 2020, esto entendemos que se debe a la reducción de actividad servicios e industrial durante la pandemia.
- El mes que mayor consumo presenta es julio, lo cual es entendible debido al uso de aparatos de aire acondicionado.
- El segundo trimestre es el que presenta valores más bajos de consumo, destacando abril como el mes con valores más bajos.
A continuación, dividimos la tabla de datos en set de entrenamiento y en set de validación. El set de entrenamiento se utiliza para entrenar el modelo, es decir, el modelo aprende a predecir el valor de la variable objetivo a partir de dicho set, mientras que el set de validación se utiliza para evaluar el rendimiento del modelo, es decir, el modelo se evalúa con los datos de dicho set para determinar su capacidad para predecir los nuevos valores.
Esta división de los datos es importante para evitar el sobreajuste siendo la proporción típica de los datos que se utilizan para el set de entrenamiento de un 70 % y el set de validación del 30% aproximadamente. Para este ejercicio hemos decidido generar el set de entrenamiento con los datos comprendidos entre el "01-01-2019" hasta el "01-10-2021", y el set de validación con los comprendidos entre el "01-10-2021" y el "31-12-2022" como podemos apreciar en la siguiente gráfica.

Figura 4. Serie temporal de datos históricos dividida en set de entrenamiento y set de validación
Para este tipo de ejercicio, tenemos que utilizar algún algoritmo de regresión. Existen diversos modelos y librerías que pueden utilizarse para predicción de series temporales. En este ejercicio utilizaremos el modelo “Gradient Boosting”, modelo de regresión supervisado que se trata de un algoritmo de aprendizaje automático utilizado para predecir un valor continúo basándose en el entrenamiento de un conjunto de datos que contienen valores conocidos para la variable objetivo (en nuestro ejemplo la variable “valor”) y los valores de las variables independientes (en nuestro ejercicio los atributos temporales).
Está basado en árboles de decisión y utiliza una técnica llamada "boosting" para mejorar la precisión del modelo siendo conocido por su eficiencia y capacidad para manejar una variedad de problemas de regresión y clasificación.
Sus principales ventajas son el alto grado de precisión, su robustez y flexibilidad, mientras que alguna de sus desventajas son la sensibilidad a valores atípicos y que requiere una optimización cuidadosa de los parámetros.
Utilizaremos el modelo de regresión supervisado ofrecido en la librería XGBBoost, el cuál puede ajustarse con los siguientes parámetros:
- n_estimators: parámetro que afecta al rendimiento del modelo indicando el número de árboles utilizados. Un mayor número de árboles generalmente resulta un modelo más preciso, pero también puede llevar más tiempo de entrenamiento.
- early_stopping_rounds: parámetro que controla el número de rondas de entrenamiento que se ejecutarán antes de que el modelo se detenga si el rendimiento en el conjunto de validación no mejora.
- learning_rate: controla la velocidad de aprendizaje del modelo. Un valor más alto hará que el modelo aprenda más rápido, pero puede provocar un sobreajuste.
- max_depth: controla la profundidad máxima de los árboles en el bosque. Un valor más alto puede proporcionar un modelo más preciso, pero también puede provocar un sobreajuste.
- min_child_weight: controla el peso mínimo de una hoja. Un valor más alto puede ayudar a prevenir el sobreajuste.
- gamma: controla la cantidad de reducción de la pérdida esperada que se necesita para dividir un nodo. Un valor más alto puede ayudar a prevenir el sobreajuste.
- colsample_bytree: controla la proporción de las características que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
- subsample: controla la proporción de los datos que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
Estos parámetros se pueden ajustar para mejorar el rendimiento del modelo en un conjunto de datos específico. Se recomienda experimentar con diferentes valores de estos parámetros para encontrar el valor que proporciona el mejor rendimiento en tu conjunto de datos.
Por último, mediante una gráfica de barras observaremos de forma visual la importancia de cada uno de los atributos durante el entrenamiento del modelo. Se puede utilizar para identificar los atributos más importantes en un conjunto de datos, lo que puede ser útil para la interpretación del modelo y la selección de características.

Figura 5. Gráfica de barras con importancia de los atributos temporales
4.4 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 4 del Notebook.
Una vez entrenado el modelo, evaluaremos cómo de preciso es para los valores conocidos del set de validación.
Podemos evaluar de forma visual el modelo ploteando la serie temporal con los valores conocidos junto a las predicciones realizadas para el set de validación como se muestra en la siguiente figura.

Figura 6. Serie temporal con los datos del set de validación junto a los de la predicción
También podemos evaluar de forma numérica la precisión del modelo mediante distintas métricas. En este ejercicio hemos optado por utilizar la métrica del error porcentual absoluto medio (MAPE), el cuál ha sido de un 6,58%. La precisión del modelo se considera alta o baja dependiendo del contexto y de las expectativas en dicho modelo, generalmente un MAPE se considera bajo cuando es inferior al 5%, mientras que se considera alto cuando es superior al 10%. En este ejercicio, el resultado de la validación del modelo puede ser considerado un valor aceptable.
Si quieres consultar otro tipo de métricas para evaluar la precisión de modelos aplicados a series temporales, puedes consultar el siguiente enlace.
4.5 Predicciones valores futuros
Este apartado podrás encontrarlo en el punto 5 del Notebook.
Una vez generado el modelo y evaluado su rendimiento MAPE = 6,58 %, pasamos a aplicar dicho modelo al total de datos conocidos, con la finalidad de predecir los valores de consumo eléctrico no conocidos del 2023.
En primer lugar, volvemos a entrenar el modelo con los valores conocidos hasta finales del 2022, sin dividir en set de entrenamiento y validación. Por último, calculamos los valores futuros para el año 2023.
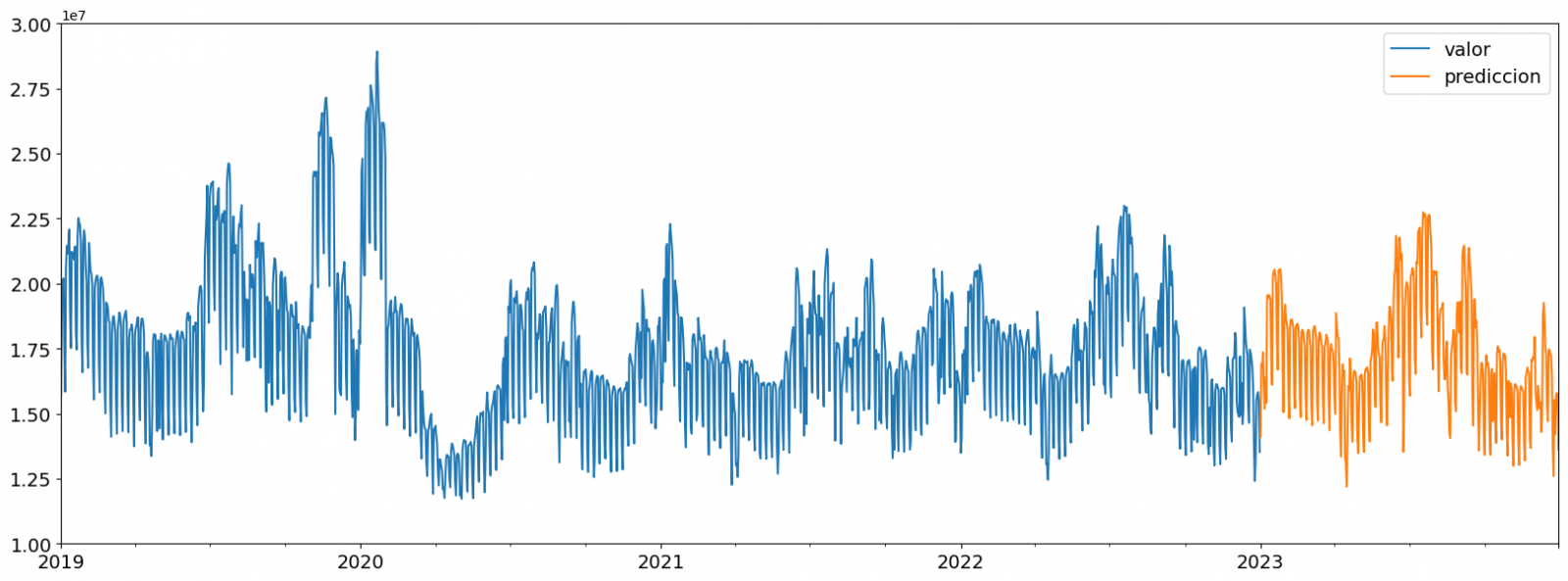
Figura 7. Serie temporal con los datos históricos y la predicción para el 2023
En la siguiente visualización interactiva puedes observar los valores predichos para el año 2023 junto a sus principales métricas, pudiendo filtrar por periodo temporal.
Mejorar los resultados de los modelos predictivos de series temporales es un objetivo importante en la ciencia de datos y el análisis de datos. Varias estrategias que pueden ayudar a mejorar la precisión del modelo del ejercicio son el uso de variables exógenas, la utilización de más datos históricos o generación de datos sintéticos, optimización de los parámetros, …
Debido al carácter divulgativo de este ejercicio y para favorecer el entendimiento de los lectores menos especializados, nos hemos propuesto explicar de una forma lo más sencilla y didáctica posible el ejercicio. Posiblemente se te ocurrirán muchas formas de optimizar el modelo predictivo para lograr mejores resultados, ¡Te animamos a que lo hagas!
5. Conclusiones ejercicio
Una vez realizado el ejercicio, podemos apreciar distintas conclusiones como las siguientes:
- Los valores máximos para las predicciones de consumo en el 2023 se dan en la última quincena de julio superando valores de 22.500.000 MWh
- El mes con un mayor consumo según las predicciones del 2023 será julio, mientras que el mes con un menor consumo medio será noviembre, existiendo una diferencia porcentual entre ambos del 25,24%
- La predicción de consumo medio diario para el 2023 es de 17.259.844 MWh, un 1,46% inferior a la registrada entre los años 2019 y 2022.
Esperemos que este ejercicio te haya resultado útil para el aprendizaje de algunas técnicas habituales en el estudio y análisis de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!









