Docentes de los centros educativos públicos de Castilla y León



Fecha del documento: 29-09-2021
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.

Visualización del personal docente de Castilla y León clasificados por Provincia, Localidad y Especialidad docente
2. Objetivos
El objetivo principal de este post es aprender a tratar un conjunto de datos desde su descarga hasta la creación de uno o varios gráficos interactivos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre los docentes y alumnos matriculados en los centros públicos de Castilla y León durante el año académico 2019-2020. A partir de estos datos se realizan análisis de varios indicadores que relacionan docentes, especialidades y alumnado matriculado en los centros de cada provincia o localidad de la comunidad autónoma.
3. Recursos
3.1. Conjuntos de datos
Para este estudio se han seleccionado conjuntos de datos de la temática Educación publicados por la Junta de Castilla y León, disponibles en el portal de datos abiertos datos.gob.es. Concretamente:
- Dataset de las plantillas jurídicas de los centros públicos de Castilla y León de todos los cuerpos de profesorado, a excepción de los maestros, durante el curso académico 2019-2020. Este dataset se encuentra desagregado por especialidad del docente, centro educativo, localidad y provincia.
- Dataset de las matriculaciones de alumnos en centros educativos durante el curso académico 2019-2020. Este conjunto de datos se obtiene a través de una consulta que admite diferentes parámetros de configuración. Las instrucciones para realizarla se encuentran disponibles en el mismo punto de descarga del dataset. El conjunto de datos se encuentra desagregado por centro educativo, localidad y provincia.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado el lenguaje de programación Python (versión 3.7) y JupyterLab (versión 2.2), herramientas que encontrarás integradas en Anaconda, una de las plataformas más populares para instalar, actualizar o administrar software para trabajar con Data Science. Todas estas herramientas son abiertas y están disponibles de forma gratuita.
JupyterLab es una interfaz de usuario basada en web que proporciona un entorno de desarrollo interactivo donde el usuario puede trabajar con los denominados cuadernos Jupyter sobre los que podrás integrar y compartir fácilmente texto, código fuente y datos.
Para la creación de la visualización interactiva se ha usado la herramienta de Kibana (versión 7.10).
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Logstash, Beats y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch.
Si quieres conocer más sobre estas herramientas u otras que pueden ayudarte en el tratamiento y la visualización de datos, puedes ver el informe "Herramientas de procesado y visualización de datos", actualizado recientemente.
4. Tratamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son consistentes y confiables.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas! Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de Github. La forma de proporcionar el código es a través de un documento realizado sobre JupyterLab que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla.
4.1. Instalación y carga de librerías
Lo primero que debemos hacer es importar las librerías para el pre-procesamiento de los datos. Hay muchas librerías disponibles en Python pero una de las más populares y adecuada para trabajar con estos conjuntos de datos es Pandas. La librería Pandas es una librería muy popular para manipular y analizar conjuntos de datos.
4.2. Carga de datasets
En primer lugar descargamos los conjuntos de datos del catálogo de datos abiertos datos.gob.es y los cargamos en nuestro entorno de desarrollo como tablas para explorarlos y realizar algunas tareas básicas de limpieza y procesado de datos. Para la carga de los datos recurriremos a la función read_csv(), donde le indicaremos la url de descarga del dataset, el delimitador (";" en este caso) y, para que interprete correctamente los caracteres especiales como las letras con tildes o "ñ" presentes en las cadenas de texto del conjunto de datos, le añadimos el parámetro "encoding" que ajustamos al valor "latin-1".
La columna "Municipio" de la tabla "alumnos" está compuesta por el código del municipio y el nombre del mismo. Debemos dividir esta columna en dos, para que su tratamiento sea más eficiente.
4.3. Creación de una nueva tabla
Una vez que tenemos ambas tablas con las variables de interés, creamos una nueva tabla resultado de su unión. La variables de unión serán: "Localidad" en la tabla de "docentes" y "Nombre_Municipio" en la de "alumnos".
4.4. Exploración del conjunto de datos
Una vez que disponemos de la tabla que nos interesa, debemos dedicar un tiempo a explorar los datos e interpretar cada variable. En estos casos es de enorme utilidad disponer del diccionario de datos que siempre debe acompañar a cada dataset descargado para conocer todos sus detalles, pero en esta ocasión no disponemos de esta esencial herramienta. Observando la tabla, además de interpretar las variables que lo integran (tipos de datos, unidades, rangos de valores), podemos detectar posibles errores como variables mal tipificadas o la presencia de valores perdidos (NAs) que pueden restar capacidad de análisis.
En la salida de esta sección de código, podemos observar las principales características que presenta la tabla:
- Contiene un total de 4.512 registros
- Está compuesto de 13 variables, 5 variables numéricas (de tipo entero) y 8 variables de tipo categórico (tipo "object")
- No hay ausencia de valores.
Una vez que conocemos la estructura y contenido de la tabla, debemos rectificar errores, como es el caso de la transformación de algunas de las variables que no están tipificadas de manera adecuada, por ejemplo, la variable que alberga el código del centro ("Código.centro").
Una vez que tenemos la tabla libre de errores, obtenemos una descripción de las variables numéricas, "Plantilla" y "Matriculaciones", que nos ayudará a conocer detalles importantes. En la salida del código que presentamos a continuación observamos la media, la desviación estándar, el número máximo y mínimo, entre otros descriptores estadísticos.
4.5. Guardar el dataset
Una vez que tenemos la tabla libre de errores y con las variables que nos interesa graficar, lo guardaremos en una carpeta de nuestra elección para usarla posteriormente en otras herramientas de análisis o visualización. Lo guardaremos en formato CSV codificada como UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta que usemos posteriormente.
5. Creación de la visualización sobre los docentes de los centro educativos públicos de Castilla y León usando la herramienta Kibana
Para la realización de esta visualización hemos usado la herramienta Kibana en nuestro entorno local. Para realizarla es necesario tener instalado y en funcionamiento Elasticsearch y Kibana. La compañía Elastic nos pone a disposición toda la información sobre la descarga e instalación en este tutorial.
A continuación se adjuntan dos vídeo tutoriales, donde se muestra el proceso de realización de la visualización y la interacción con el dashboad generado.
En este primer vídeo, podrás ver la creación del cuadro de mando (dashboard) mediante la generación de diferentes representaciones gráficas, siguiendo los siguientes pasos:
- Cargamos la tabla de datos previamente procesados en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
- Gráfico de sectores donde mostrar la plantilla docente por provincia, localidad y especialidad.
- Métricas del número de docentes por provincia.
- Gráfico de barras, donde mostraremos el número de matriculaciones por provincia.
- Filtro por provincia, localidad y especialidad docente.
- Construcción del dashboard.
En este segundo vídeo, podrás observa la interacción con el cuadro de mando (dashboard) generado anteriormente.
6. Conclusiones
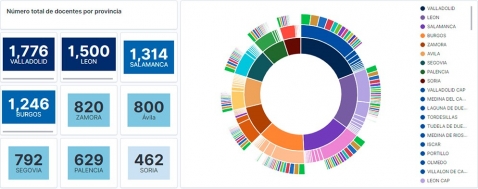
Observando la visualización de los datos sobre el número de docentes de los centros educativos públicos de Castilla y León, en el curso académico 2019-2020, se pueden obtener, entre otras, las siguientes conclusiones:
- La provincia de Valladolid es la que posee el mayor número de docentes e igualmente, el mayor número de alumnos matriculados. Mientras que Soria es la provincia con menor número de docentes y menor número de alumnos matriculados.
- Como era de esperar, las localidades que presentan mayor número de docentes son las capitales de provincia.
- En todas las provincias, la especialidad con mayor número de alumnos es Inglés, seguida de Lengua Castellana y Literatura y Matemáticas.
- Llama la atención, que la provincia de Zamora, aunque posee un número bajo de alumnos matriculados, está en quinta posición en el número de docentes.
Esta sencilla visualización nos ha ayudado a sintetizar una gran cantidad de información y a obtener una serie de conclusiones a golpe de vista, y si fuera necesario tomar decisiones en función de los resultados obtenidos. Esperamos que os haya resultado útil este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!